알고리즘에서 쓰이는 수학 정리
모듈러 연산 (Modular Arithmetic)
컴퓨터는 변수에 저장할 수 있는 수(정수)의 범위가 한정되어 있기 때문에, 결과가 큰 수로 표현될 가능성이 있는 연산의 경우 해당 연산을 부분적으로 나눠야 할 필요가 있다. 이를 모듈러 연산이라고하며 주로 답을 어떤 수로 나눠서 출력하라는 식으로 문제에서 발견할 수 있다.
- (A+B) mod M = ((A mod M) + (B mod M)) mod M
- (AB) mod M = ((A mod M) (B mod M)) mod M
- 나누기의 경우에는 성립하지 않는다. 이때 사용하는 것이 (Modular Inverse이다.)
- 뺄셈의 경우, 먼저 모듈러 연산한 요소가 음수가 나올 수 있기 때문에 조금 다른 식을 사용한다. (A-B) mod M = ((A mod M) – (B mod M) + M) mod M
% Modular Inverse (A/B) mod M = ( A mod M * (B^(M-2)) mod M
최대 공약수
가장 간단하게 구하는 방법은 2부터 min(A,B)까지 모든 정수로 나눠서 구하는 방법이다.
int g = 1;
for (int i = 2; i < min(a, b); i++)
{
if (a%i == 0 && b % i == 0)
{
g = i;
}
}
위의 코드를 살펴보면 알게 되겠지만, 이것은 모든 경우의 수를 완전 탐색하는 방식이다. 즉, 시간 복잡도에 대한 어느 최적화도 존재하지 않는다. 이것은 대상의 수가 매우 클 때 비효율적인 방식으로 알려져 있다. 그러므로 유클리드 호제법을 주로 사용하게 된다.
int gcd(int x, int y)
{
while (y != 0)
{
int r = x%y;
x = y;
y = r;
}
return x;
}
위의 코드를 재귀로 물론 작성할 수 있지만 입력으로 들어오는 두 수의 크기 차이가 커지면 커질수록 스택이 나갈 가능성도 같이 커지기 때문에 반복문으로 작성하는게 맘편한 방향이다.
가끔 세수의 최대 공약수를 구해야 할 때도 존재한다. 이럴 경우에는 다음과 같이 구한다.
GCD(a,b,c) = GCD(GCD(a,b),c) -> 생각해보면 간단한 수학 개념이다. 숫자가 늘어나면 같은 방식으로 구해야한다.
최소 공배수
최소 공배수는 GCD를 응용해서 구할 수 있다. 두 수의 최대 공약수를 g라고 했을 때,
최소공배수는 g(a/g)(b/g)라고 생각해도 된다. 왜냐하면 a와 b가 서로소라고 했을 때 최대공약수는 그 서로소들에다 공약수를 곱한 수이기 때문이다.
소인수 분해
정수 N을 소수의 곱으로 분해하는 것이다. 소수를 구하지 않고도 해결할 수 있다고 한다. N을 소인수분해 했을 때, 나타날 수 있는 인수 중에서 가장 큰 값은 루트 N이다. 따라서 2부터 루트N까지 반복문을 돌면서 N을 나눌 수 있다면 마지막까지 계속 나누면 된다.
for (int i = 2; i*i; ++i)
{
while (n%i == 0)
{
printf("%d\n", i);
n /= i;
}
}
if (n > 1) //마지막이 1보다 커야 소인수로서 의미가 있으므로…
printf("%d\n", n);
만약 코딩이나 알고리즘 공부의 기간이 그리 길지 않은 사람이라면 이런 질문을 날릴 수도 있을 것 같다. ‘이 코드에 따르면 4역시 포함되버리지 않나요?’
하지만 조금만 더 생각해보자. 2의 순서가 되었을 때 2가 나눠지지 않을 때까지 반복하기 때문에 결국 2의 배수 4로 나누는 것은 근본적으로 불가능해 진다.
팩토리얼
고등학교때 배운 기억이 난다. 순열 조합파트에서 공부했던 기본 개념 중 하나로, N!이라면 1부터 N까지 모든 수의 곱을 나타낸다. 이것을 컴퓨터에서 코딩으로 구한다고 치면 사실 부담이 생긴다. 로직이 어려운 것 보다는 연산의 종류가 곱셈에 속하기 때문에 결과값이 기하 급수적으로 커질 가능성이 있기 때문이다. 항상 결과값을 대입하는 변수의 자료형에 대해 고민하자.
거듭제곱의 분할 정복
거듭 제곱의 한 형태, a^b의 연산은 보통 다음과 유사하게 할 것이다.
int ans = 1;
for (int i = 1; i <= b; ++i)
{
ans = ans * a;
}
굉장히 직관적이지만 시간 복잡도에서 O(b)을 벗어나기 힘들다. 이것 또한 구하는 수가 커지면 사용하기 어려워지는 방법이다.
이럴 때 사용할 수 있는 것이 분할정복이다.
예를 들면 a^2b는 a^b a^b라고 생각할 수 있다. 또한 a^(2b+1)은 a a^2b라는 직관적인 식이 나온다. 이 개념을 이용하여 거듭제곱 함수를 다시 코딩해보자.
int calc(int a, int b)
{
if (b == 0)
{
return 1;
}
else if (b % 2 == 0)
{
int temp = calc(a, b / 2);
return temp*temp;
}
else
{
int temp = calc(a, b - 1);
return a * temp;
}
}
너무나 직관적인 로직이어서 따로 해석할 필요가 없을 정도이다. 하지만 이 모듈을 작성하는데까지의 사고 논리는 알고리즘 문제풀이에 굉장히 유용한 듯 하다.
위의 방식뿐만 아니라 이진수의 원리를 이용해서도 구할 수 있다.
int calc2(int a, int b)
{
int ans = 1;
while (b > 0)
{
if (b % 2 == 1)
ans *= a;
a = a * a;
b /= 2;
}
return ans;
}
위의 코드에서 a를 거듭제곱하고 b를 절반으로 나누는 것은 제곱한 값을 다시 제곱하기 때문이다. 만약 이해가 되지 않는다면 위의 코드를 디버깅하면서 관찰하자.
이항계수
조합문제의 연장선상이다. N개 중에서 k개를 순서 없이 고르는 방법을 의미한다. 단순하게 수식에 따라서 팩토리얼 연산 3번하는 것도 방법이 될 수 있지만, 숫자가 커지면 커질수록 연산의 수가 기하급수적으로 늘어난다. 이럴때는 파스칼의 삼각수로 해결하며 이 과정에서 메모이제이션이 발생하여 시간을 획기적으로 줄일 수 있다. 점화식은 다음과 같다.
C[n][k] = C[n-1][k-1] + C[n-1][k]
문제는 이 방법을 사용한다고 해도 입력의 크기가 더 커지면 똑같이 연산에 대해 문제가 생긴다는 것이다. 그래서 이럴 때 사용하라고 뤼카의 정리라는 것을 공부해보려한다.
뤼카의 정리란 음이 아닌 정수 n,k, 소수 p에 대해 n,k를 p진법으로 전개했을 때 다음과 같이 나온다면
 다음 식이 성립함을 말한다.
다음 식이 성립함을 말한다.

예를 들어 다음과 같은 식이 있다고 하자.
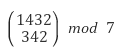
이것을 7진법으로 바꾼다.

하지만 여기서 다음과 같은 조건이 나오면 처리하는 규칙이 발생한다.
 <
그러므로 이 예시의 답은 0임을 알 수 있다.
<
그러므로 이 예시의 답은 0임을 알 수 있다.
오일러 피 함수 (Euler’s phi Function)
F(n) = gcd(n,k) = 1인 1<=k<=n의 개수를 말한다.
F(9) = 6이면 k = 1,2,4,5,7,8이다.
생각해보면 소수의 개수를 구하는 것과 같은 문제이다.
특징을 정리하면 다음과 같다.

이론적으로는 상당히 간단하다. 결국 n보다 작은 수를 계속 나눠가면서(결국 소수들을 추출해 갈 것이다. 개수를 빼주는 것이다.) 이것을 코드로 작성하면 다음과 같다.
long long phi(long long n)
{
long long ans = n;
for (long long i = 2; i*i <= n; ++i)
{
if (n%i == 0)
{
while (n%i == 0)
n /= i;
ans -= ans / i;
}
}
if (n > 1)
ans -= ans / n;
return ans;
}
확장 유클리드 알고리즘
유클리드 알고리즘을 이용해서 ax+by = gcd(a,b)를 만족하는 정수해 x, y를 쉽게 구할 수 있는 알고리즘이다. 대부분의 경우에 a와 b중 하나는 음수가 나온다고 한다.
부정방정식 ax+by = c에서 c값이 gcd(a,b)의 배수 형태일 경우에만 정수해를 가진다. 그러므로 c의 최소값은 gcd(a,b)이다.
유클리드 알고리즘을 이용했을 때 gcd(a, b)는
- a = b*q1+r1
- b = r1*q1 + r2
- r1 = r2*q3 +r3
이라는 기본형이 나오게 될 것이고 r1, r2, r3을 기준으로 정리한다면 - r1 = a – b*q1
- r2 = b – r1*q2
- r3 = r1 – r2*q3
이 되어 원하는 값을 전부 구할 수 있다. 이렇게 한다면 정수해 x, y를 모두 구할 수 있다.
확장 유클리드 알고리즘
유클리드 알고리즘을 이용해서 ax+by = gcd(a,b)를 만족하는 정수해 x, y를 쉽게 구할 수 있는 알고리즘이다. 대부분의 경우에 a와 b중 하나는 음수가 나온다고 한다.
부정방정식 ax+by = c에서 c값이 gcd(a,b)의 배수 형태일 경우에만 정수해를 가진다. 그러므로 c의 최소값은 gcd(a,b)이다.
유클리드 알고리즘을 이용했을 때 gcd(a, b)는
- a = b*q1+r1
- b = r1*q2 + r2
- r1 = r2*q3 +r3
이라는 기본형이 나오게 될 것이고 r1, r2, r3을 기준으로 정리한다면 - r1 = a – b*q1
- r2 = b – r1*q2
- r3 = r1 – r2*q3
이 되어 원하는 값을 전부 구할 수 있다. 이렇게 한다면 정수해 x, y를 모두 구할 수 있다. 그것에대한 자세한 과정은 다음과 같으며, ax+by = gcd(a, b)의 해는 마지막 이전에 나오는 s와 t값이 x와 y가 된다.

%% ax+by = 1일 때, x는 a의 나머지 연산의 곱셈 역원이 된다. 그러므로 굉장히 유용하게 사용할 수 있다고 한다. 시간 복잡도가 작기 때문이다.
정렬
정렬에 관련해서 많은 알고리즘이 있다. 예를 들어 선택 정렬, 버블 정렬, 삽입 정렬, 퀵 정렬, 힙 정렬, 병합 정렬 등등.
정렬은 기본적으로 O(NlogN)이 걸리는 정렬을 사용하는 것이 좋다. 또한 직접 구현하기 보다는 STL에 있는 sort를 사용하는 것이 좋다고 한다.
STL에 있는 함수인 sort(begin, end)를 사용하면 begin부터 end바로 전까지를 정렬할 수 있다. 만약 자신만의 정렬 로직을 추가하고 싶으면 비교 함수를 작성하여 sort함수의 3번째 인자로 넣는다.